序言
从P5开始,我们迎来了崭新的篇章,5级流水线。我真的想不出什么其他词汇来形容他的伟大,总之他让无数学生为之倾倒,也让少数情侣为之分道扬镳(别怕)。从这一章节开始,我们设计的CPU难度有了质的飞跃。
相信很多同学在听了计组理论课关于阻塞和转发的讲解后一头雾水,看了学长的代码之后仍然有一万个为什么。这篇文章笔者将以五级流水线的具体设计为主线,尽可能地解答大家在设计过程中遇到的疑惑,希望能给大家带来一些帮助,如有不详尽之处还请大家多多包涵,也欢迎大家批评指正。
关于命名方式的一些Tips
在五级流水线的设计中我们会遇到数不尽的端口,如果命名方式不合理,可能我们在 VScode 的提示下也会云里雾里,但是如果我们有一套自己的命名规则,那么我们可以清楚地识别哪些是端口名称,哪些是连线(实例化时的wire型变量)的名称,从而极大地缩减编码时的工作量和bug率。
笔者习惯将端口名称大写,将连线名称小写,(clk和reset除外)虽然这种方式不能借助ISE的实例化工具完成,但是至少于编程者而言各变量的含义了然于心,不会越编越乱,以至于自己都不知道自己在干什么。怎么说呢,每个人有每个人独特的方式,大家只要探索到适合自己的命名方式就好。
设计综述
五级流水线,顾名思义,当然要弄清楚是哪五级,以及分别有哪些流水线寄存器,以及每一级都包含哪些元件。
F级: IFU
D级:CMP,EXT,GRF,NPC,D_reg
E级:E_ALU,E_reg
M级:M_DM,M_reg
W级:W_reg
显然,五级流水线,四个流水线寄存器,构成了P5设计的基本框架。除此之外,还有Stall模块用来处理阻塞,mips模块在组装元件的过程中实现转发,def模块定义一些宏,CTRL模块实现控制信号以及配合Stall模块实现阻塞判断。
设计图可以参照: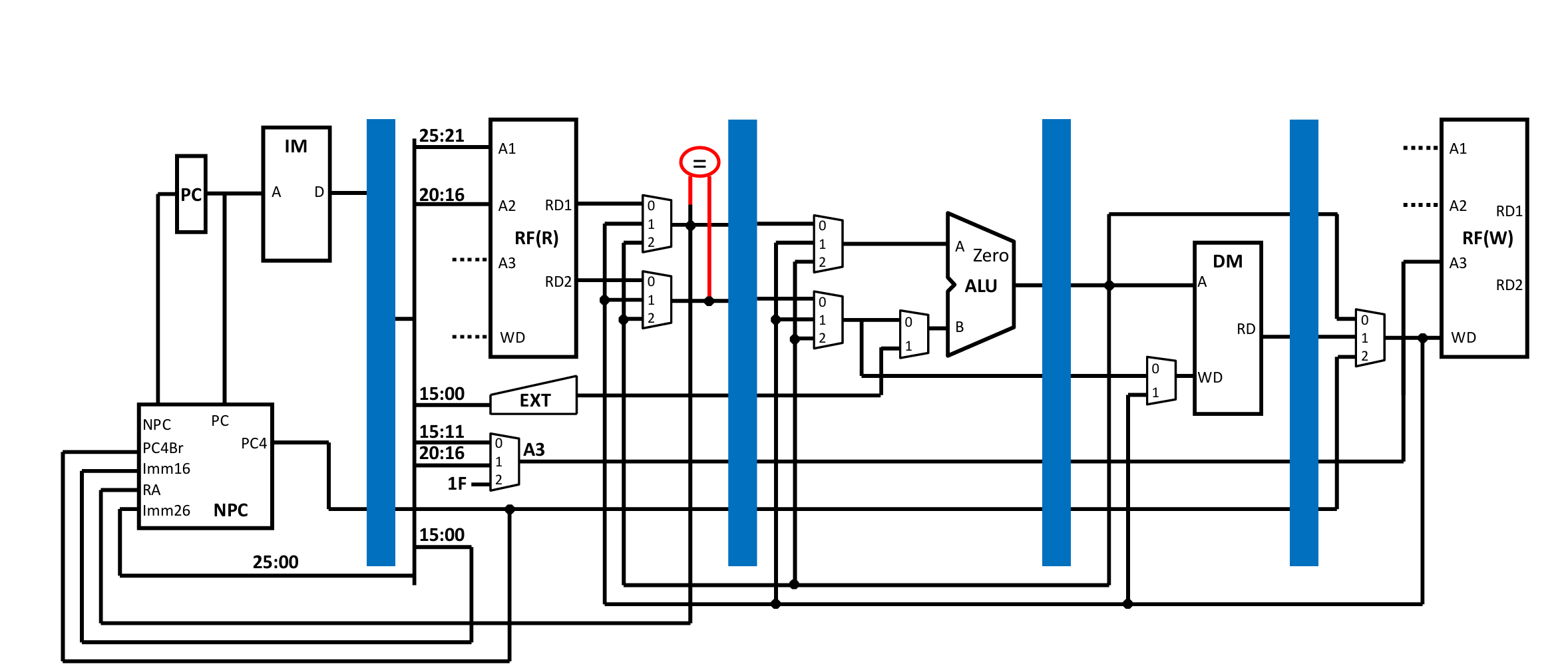
P5课下要求实现的指令是:add, sub, ori, lw, sw, beq, lui, jal, jr, nop。由于接口繁多,笔者在搭建时本着接口能少就少的原则完成设计,(当然也要给课上留好一定的扩展接口)。
在大家大概了解了每一个模块的作用以及我们要实现的具体指令以后我们就可以进入详细的设计分析了。
F_IFU
module F_IFU ( |
F_IFU和P4相比变化不大只是在输入中新增了PCWE。当Stall生效时,IFU中的PC不再更新,直到阻塞结束。
D_reg
module D_reg ( |
D级寄存器负责连接F级和D级流水线,因为课程组规定阻塞只能发生在D级,因此当阻塞指令生效时,WE禁止向D级寄存器写入指令,Flush刷新E级寄存器为nop,从而使得nop信号随着流水线流下去,从而实现阻塞。
Q: PC和Instr要一直流水下去吗?
A: 是的。只有PC和instr随流水线一直流水下去我们才能判断每一级流水线的当前指令是什么。
instr主要用途:阻塞判断,每一级流水线译码(分布式)。
PC主要用途:DM要输出PC,jal指令向GPR[rs]写入涉及PC,
D_EXT
module D_EXT ( |
EXT和P4没有什么区别。
D_CMP
module D_CMP ( |
D_CMP存在的意义是将BEQ的比较提前,这样可以尽早判断是否跳转,减少流水线的”白流”。
D_NPC
module D_NPC ( |
在D_NPC模块的接口相较于P4多出了Beq_jump,F_PC,D_PC三个信号。Beq_jump不必赘述,我们重点区分一下F_PC和D_PC以及他们的用法。
首先大家需要明确,在一般情况下:F_PC = D_PC + 4。(因为流水线走了一级嘛)。
接着我们来看一个流水线简图:
| 时钟周期 | F级(取指) | D级(译码) | E级(执行) | M级(访存) | W级(写回) |
|---|---|---|---|---|---|
| 拍1 | 取 BEQ(0x00) | - | - | - | - |
| 拍2 | 取下条 A(0x04) | 译 BEQ(0x00)并判断 | - | - | - |
| 拍3 | 取下下条 B(0x?) | 译下条 A(0x04) | 执行BEQ对地址的更改 | - | - |
我们可以采用类似延迟槽的思想,A指令无论如何都会被执行,那么我们重点考虑B指令。
如果 Beq_jump = 0,我们应该接着F_PC取PC + 4,这也就决定了assign PC_4 = F_PC + 4;
如果 Beq_jump = 1,那我们根据Beq的RTL语言。PC+4使用的应该是D_PC,这也决定了assign IMM_BEQ = {{14{IMM[15]},IMM[15:0],2'b0}} + D_PC + 4。
根据上述分析,我们可以同理得出,assign IMM_J_Jal = {D_PC[31:28],IMM,2'b0}
D_GRF
module D_GRF ( |
在GRF这个模块,虽然模块名称叫D_GRF(因为这里理论上只读,在W级才执行写操作),但是由于全局GRF的唯一性,我们保留了WD,A3这两个写入数据必要的接口,当指令流水到W级时,根据A3是否等于0来决定是否写入。
为什么是根据A3是否等于0来决定是否写入呢,因为我们在这里为了简化设计采用了隐式写使能,即取消显式WE信号,转而通过A3的取值来决定是否写入GRF。
if (A3 != 0) begin |
对于A3的取值,CTRL模块会出手的,我们在CTRL会详细解释,这里大家只要留个印象即可。因为是在W级流水线写入,所以聪明的你应该可以感觉到WD,A3在mips模块实例化时对应的wire是什么了吧,没猜到也没关系,我们接着往下看。
assign RD1 = (A1 == 0) ? 32'b0 : (A1 == A3) ? WD : register[A1]; |
这段代码翻译过来就是,如果访问0号寄存器,直接给出0,如果访问的寄存器和A3冲突,那就给出WD的值,如果都不是,那就正常给出register[A1]。
当进入A1和A3冲突的分支时,那么A3一定不为0,相当于写使能有效。这段代码的作用就更加明显:**如果访问的寄存器和W级流水线将要写入的寄存器冲突,那么给出的值是将要写入的WD而不是现在的寄存器值register[A1]**。
这就是转发!!!只不过这是GRF内部转发,我们在mips模块中大量实现的是外部转发。大家还是留个印象,到时候再说😁。
E_reg
module E_reg ( |
E_reg的接口相较于D_reg又多了D_EXT,D_Rs_data,D_Rt_data,这三个量都是E级不可或缺的变量,所以也没什么可说的😥。
E_ALU
module E_ALU ( |
这个也再正常不过了,我们下一个。
M_reg
module M_reg ( |
M_reg相较于E_reg多了E_C,这是ALU计算出的结果,肯定要往后流水,M级和W级都要用。少了的就是没用了,端口太多,全传过去有点抽象😥。
M_DM
module M_DM ( |
W_reg
module W_reg ( |
至此,我们完成了各个元件的搭建,其实P5和P4相比,这些基本元件几乎没变,变的是CTRL,mips,还新增了Stall。
接下来就是P5的核心,也是最难的部分————阻塞与转发。
CTRL
CTRL是译码器,主流的有两种设计方式:
集中式译码 :在取指令(F 级)时或者读取寄存器阵列信息(D 级)前,将所有的控制信号全部解析出,然后让其随着流水往后逐级传递。
分布式译码 :每一级都部署一个译码器,负责译出当前级所需控制信号。
为了尽可能减少一个模块中的接口数量,这里采用分布式译码。在设计CTRL模块时输出包含所有的控制信号以及rs,rt…在每一级可能会用到的信号,在mips模块中只需要在每一级流水线译出该级流水线所需的信号即可。
module CTRL ( |
控制信号具体值可以参看译码表。如图:
| 指令 | opcode(31:26) | funct(5:0) | EXTOp | CMPOp | NPCOp | ALUOp | ALUBSel | GRFWDSel | GRFA3Sel | DMWE |
|---|---|---|---|---|---|---|---|---|---|---|
| 功能 | opcode | func | 立即数扩展 | 比较器操作 | 下一条PC计算 | ALU运算 | ALUB端口选择 | GRF写回数据来源 | GRF写回地址选择 | 数据存储器写使能 |
| add | 000000 | 100000 | EXT_ZERO | CMP_BEQ | NPC_PC4 | ALU_add | ALUBrt | GRFWDALU | GRFA3rd | DMWE_ZERO |
| sub | 000000 | 100010 | EXT_ZERO | CMP_BEQ | NPC_PC4 | ALU_sub | ALUBrt | GRFWDALU | GRFA3rd | DMWE_ZERO |
| ori | 001101 | x | EXT_ZERO | CMP_BEQ | NPC_PC4 | ALU_ori | ALUBimm | GRFWDALU | GRFA3rt | DMWE_ZERO |
| lw | 100011 | x | EXT_SIGN | CMP_BEQ | NPC_PC4 | ALU_add | ALUBimm | GRFWDDM | GRFA3rt | DMWE_ZERO |
| sw | 101011 | x | EXT_SIGN | CMP_BEQ | NPC_PC4 | ALU_add | ALUBimm | GRFWDALU | GRFA3rt | DMWE_ONE |
| beq | 000100 | x | EXT_ZERO | CMP_BEQ | NPC_BEQ | ALU_sub | ALUBrt | GRFWDALU | GRFA3rt | DMWE_ZERO |
| lui | 001111 | x | EXT_ZERO | CMP_BEQ | NPC_PC4 | ALU_lui | ALUBimm | GRFWDALU | GRFA3rt | DMWE_ZERO |
| sll | 000000 | 000000 | EXT_ZERO | CMP_BEQ | NPC_PC4 | ALU_sll | ALUBrt | GRFWDALU | GRFA3rd | DMWE_ZERO |
| j | 000010 | x | EXT_ZERO | CMP_BEQ | NPC_J_Jal | ALU_add | ALUBrt | GRFWDALU | GRFA3rt | DMWE_ZERO |
| jal | 000011 | x | EXT_ZERO | CMP_BEQ | NPC_J_Jal | ALU_add | ALUBrt | GRFWDPC8 | GRFA331 | DMWE_ZERO |
| jr | 000000 | 001000 | EXT_ZERO | CMP_BEQ | NPC_Jr_Jalr | ALU_add | ALUBrt | GRFWDALU | GRFA3rd | DMWE_ZERO |
| jalr | 000000 | 001001 | EXT_ZERO | CMP_BEQ | NPC_Jr_Jalr | ALU_add | ALUBrt | GRFWDPC8 | GRFA3rd | DMWE_ZERO |
Stall
阻塞的概念是,当我们发现单凭转发已经不足以解决读写冲突的问题时,不得不让当前指令停在D级,直到随流水线流水的指令产生写入数据的时间(Tnew)小于等于D级指令将要读取寄存器的时间(Tuse),D级流水线寄存器才放行,在这期间一直是nop从E级不断向后流水。
这里我们对Tnew和Tuse做详细阐释:
Tuse:对于某一个指令的某一个数据需求,我们定义需求时间Tuse为:
这条指令位于 D 级的时候,再经过多少个时钟周期就必须要使用相应的数据。例如,对于 beq 指令,立刻就要使用数据,所以 Tuse = 0;对于 add 指令,等待下一个时钟周期它进入 E 级才要使用数据,所以 T_use = 1;而对于 sw 指令,在 E 级它需要 GPR[rs] 的数据来计算地址,在 M 级需要 GPR[rt] 来存入值,所以 rs_Tuse = 1,rt_Tuse = 2。
Tnew: 对于某个指令的数据产出,我们定义供给时间Tnew为:
位于某个流水级的某个指令,它经过多少个时钟周期可以算出结果并且存储到流水级寄存器里。注意是流水级寄存器,不是GRF。对于 add 指令,当它处于 E 级,此时结果还没有存储到流水级寄存器里,所以此时它的 Tnew = 1,而当它处于 M 或者 W 级,此时结果已经写入了流水级寄存器,所以此时 Tnew = 0.
当Tnew > Tuse 时,数据不能及时算出,需要通过阻塞来解决。
当Tnew <= Tuse 数据能够及时算出,可以转发解决。
由于Tnew的是一个动态值,而Tuse为一个静态值,随着Tnew的不断减小,当Tnew = Tuse 时,D级流水线寄存器就可以放行了。以上就是阻塞的大概过程,我们看具体的代码再做理解。
module STALL ( |
在D级只产生Tuse,在E,M级产生Tnew,(W级Tnew恒等于0)我们只需要分三个区间分别写出对应的Tnew,Tuse,然后列出阻塞情况,最后通过或运算就可以得到阻塞信号Stall;
assign E_stall_rs = (D_rs == E_GRFA3 && (D_rs != 0)) && (rs_Tuse < E_Tnew); |
第一行代表的含义是E级导致阻塞,rs地址冲突。注意,当rs = 0是,默认寄存器的值已知,不需要阻塞。这里附上Tnew和Tuse的阻塞表。
D_Tuse:
| 指令 | add | sub | ori | lw | sw | beq | lui | sll | j | jr | jal | jalr |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D_rs_Tuse | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 3 | 3 | 0 | 3 | 0 |
| D_rt_Tuse | 1 | 1 | 3 | 3 | 2 | 0 | 3 | 1 | 3 | 3 | 3 | 3 |
E_Tnew & M_Tnew:
| 指令 | add | sub | ori | lw | sw | beq | lui | sll | j | jr | jal | jalr |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E_Tnew | 1 | 1 | 1 | 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| M_Tnew | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
mips
阻塞处理完,我们就要开始实例化模块并连接电路了,连接过程中实现外部转发,我们的五级流水线CPU就基本搭建完成了。总体来说,我们的设计主线是模块的实例化,在实例化过程中我们会发现某个需要使用的变量的缺失,这时我们在每一级的固定定义区定义我们需要的wire类型变量即可,大家完全不必纠结于在每一个模块开始时定义什么。
特别的,E_GRFa3,E_GRFwd系列的指令需要在开头定义,因为这些指令如果在对应模块定义的话就会出现在定义前使用的情况,使用时编译器会自动隐式定义为1位的wire变量,如果你在之后再次定义的话,编译器会报错重复定义。
笔者这里在全局定义区定义了常用变量,大家可以参考这种定义方式,也可以放在固定的流水级,你开心就好😊
//各级PC和Instr |
接下来强调几个重要的模块。
stall
阻塞模块是全局变量,需要作为单独一个实例来控制各个流水线寄存器的运作,Stall的取值可能会影响的变量是PC_we,D_reg_we,E_reg_flush。
D级
D级GRF实例化时A3接口和WD接口分别接W_GRFa3和W_GRFwd,从而实现GRF内部转发。而由于W级实现了内部转发,我们在转发D_For_rs_data和D_For_rt_data时只转发E,M即可:
assign D_For_rs_data = (D_rs == 5'd0) ? 32'd0 : |
这里很多同学会问,转发时如何保证E_GRFwd,M_GRFwd已经算出来了呢,其实很简单,当你在执行转发时,是不是说明不需要阻塞了,那不需要阻塞是否意味着你要的东西已经算出来了呢?
注意D_NPC和D_CMP用的D_rs_data和D_rt_data都是转发后的。
E级
因为E级没有GRF,即没有内部转发,因此E级E_For_rs_data和E_For_rt_data需要转发M,W。并且在E级要实现E_GRFa3和E_GRFwd这两个转发必要的数据赋值,E_GRFa3实现没什么坑点,值得一提的是,E_GRFwd没有DMrd这个选项,因为在E级,还没有算出M级的结果。
注意E_ALU用的E_rs_data和E_rt_data是转发后的。
M级
M级只需要转发rt_data,因为rs_data不会在M级被使用。同理实现M_GRFa3和M_GRFwd,此时M_GRFwd有了DMrd这个选项。
注意M_DM用的M_rt_data是转发后的结果。
W级
W级没什么好转发的,只需要实现W_GRFa3和W_GRFwd即可。
Some Tips
- P5确实难,大家如果一开始上不了手也完全没关系,这不是你的问题。
- 老师会建议大家先写设计文档,再搭建CPU。听着很有道理哈,但是对于大部分同学来说听完理论课根本不知道从哪里下手,只能死磕设计文档。你可以把死磕设计文档理解成盯着markdown学P5,你就知道这种推荐行为有多搞笑了……(当然大佬除外,确实有些同学是具备直接上手设计文档的能力的)。我的建议是大家完全可以直接照着学长的博客搭一遍,搭的过程中你一定会有很多疑问,只要做标记就好,在你搭建的过程中你会对某些问题有自己的理解,在搭建完成后再把整个CPU过一遍,找出自己不理解的地方专项攻克。在做完这些工作之后你一定会对流水线CPU有更深刻的理解,这时你再把
Stall,mips,CTRL这三个重点模块自己重新写一遍,就形成了属于自己的CPU。个人感觉这种盯着代码学P5要比盯着markdown学P5好很多。 - 这篇Blog只是介绍了课下的基础指令,单凭这些工作就想P5课上过,片叶不沾身有点困难,我们还需要完善某些接口,详见关于P5课上的这篇博客。
Summary
P5作为流水线CPU的开山之P,是后面几次实验的基础,同学们要认真对待。这篇博客说了这么多,虽然不能让你在看完之后立刻原地完美搭建5级流水线CPU,但是只要其中的一些细节解释能给你些许灵感,足矣。
Lyrics Sharing
修炼爱情的悲欢 |

